 Radiomics Analysis and DAta Reproducibility
Radiomics Analysis and DAta Reproducibility
Radiomics Analysis and DAta Reproducibility
Radiomics Analysis and DAta Reproducibility
Radiomics and Deep Learning have emerged as key methodologies for extracting high-dimensional quantitative information from medical images. By transforming imaging data into mineable features or data-driven representations, these approaches aim to support diagnosis, prognosis, and treatment response assessment. Despite their rapidly growing adoption, radiomics and deep learning studies are frequently affected by limited standardization, methodological heterogeneity, and insufficient reproducibility, which continue to hinder robust clinical translation.
This challenge clearly highlights the pivotal role of close and continuous collaboration between clinicians and medical physicists. Clinicians contribute the clinical hypotheses, patient stratification criteria, and the definition of clinically relevant endpoints, while medical physicists provide the methodological framework, imaging expertise, and quantitative tools required to ensure data quality, robustness, and reproducibility. Only through this synergistic interaction is it possible to define standardized, transparent, and reliable workflows that are applicable both in research settings and in routine clinical practice.
From a practical perspective, the integration of Artificial Intelligence tools with advanced imaging techniques into clinical workflows aims not only to automate standardized processes, but also to facilitate the transition toward a new paradigm in healthcare: personalized medicine. Rather than treating patients as members of homogeneous groups defined by shared clinicopathological characteristics, this paradigm considers each patient as a unique individual, enabling the generation of objective, quantitative data that can be leveraged to develop robust and clinically meaningful predictive models.
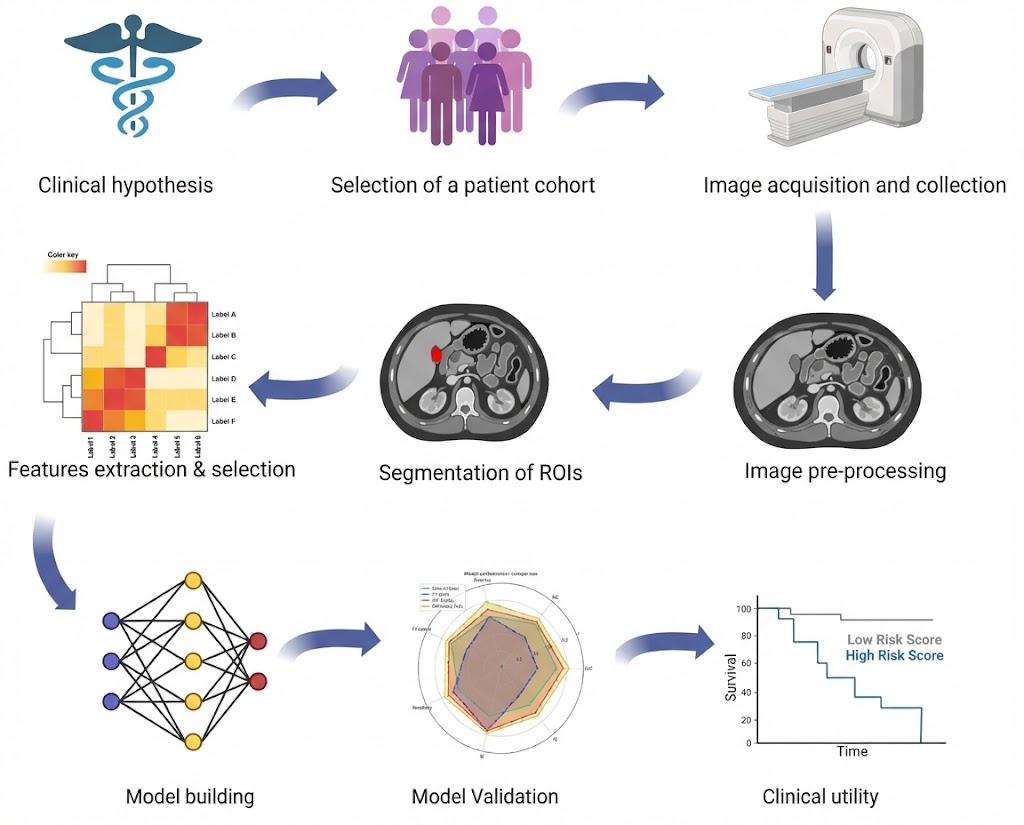
Within this multidisciplinary framework, the radiomics workflow (Figure 1) is inherently hypothesis-driven and clinically oriented. It starts from a clearly defined clinical question, followed by the selection of an appropriate patient cohort and standardized image acquisition protocols. Subsequent steps include image preprocessing to reduce technical variability, accurate segmentation of regions of interest, and extraction of quantitative features. Feature selection and model building are then performed to identify the most informative biomarkers, followed by rigorous internal and external validation to assess robustness, reproducibility, and generalizability. Ultimately, the evaluation of clinical utility is essential to determine the real added value of the model in supporting clinical decision-making and improving patient care.
To address the methodological challenges affecting radiomics and deep learning studies, several quality assessment frameworks have been proposed, including RQS 2.0 (Radiomics Quality Score) and METRICS (METhodological RadiomICs Score). These tools aim to improve reporting standards and methodological rigor by systematically evaluating key components of radiomics studies, such as study design, validation strategies, and model performance.
Although these frameworks represent important advances for the field, they are primarily based on checklist-oriented or domain-specific evaluation strategies and may only partially capture critical issues related to data reproducibility, end-to-end pipeline robustness, and machine learning–specific methodological risks. Moreover, the coexistence of multiple scoring systems has contributed to fragmented assessment practices, limiting comparability across studies and complicating evidence synthesis in systematic reviews.
These limitations highlight the need for an evaluation framework that ensures the standardization and reproducibility of the entire analytical pipeline, while simultaneously integrating methodological rigor with considerations of clinical applicability. To address this gap, RADAR was developed not as an additional checklist, but as a comprehensive and quantitative scoring framework. RADAR is specifically designed to capture both the theoretical and methodological soundness underlying the development of AI-based models in personalized medicine, as well as practical aspects related to generalizability, interpretability, and consistent future use in clinical practice. In this way, RADAR aims to support the robust translation of imaging-based AI models from research environments to real-world clinical settings.
RADAR was conceived to meet the growing demand for a standardized, reproducible, and comparable evaluation of artificial intelligence models in personalized medicine, with particular emphasis on imaging-based radiomics and deep learning applications. While multiple evaluation frameworks exist, persistent methodological heterogeneity and fragmented assessment strategies continue to limit the interpretability, reproducibility, and clinical translatability of AI-based studies.
Rather than introducing a competing score, RADAR builds upon and synergistically integrates the complementary strengths of existing frameworks, most notably RQS 2.0 and METRICS, within a single, unified, and comprehensive evaluation system. Specifically, RADAR combines the methodological rigor and study design principles emphasized by RQS 2.0 with the performance-, validation-, and machine learning–oriented criteria central to METRICS. By unifying these perspectives, RADAR enables a holistic assessment of AI models that balances theoretical soundness with practical applicability across the entire workflow.
Specifically, RADAR enables:
Importantly, RADAR is specifically designed as a practical tool for systematic reviews and meta-research in radiomics and deep learning, enabling consistent evaluation, comparison, and synthesis of evidence across heterogeneous studies using a common and transparent framework. To promote widespread adoption, RADAR provides an online calculator that allows researchers to directly apply the scoring system and obtain downloadable outputs, including structured evaluation reports and graphical representations (e.g., radar plots) for individual studies or comparative analyses.
Overall, RADAR serves as a bridge between methodological development and clinical implementation, fostering a more responsible, transparent, and effective translation of AI-based models from research environments into routine clinical practice.